Despite of the technological advances in last few decades, many organisations are still struggling to extract business intelligence out of their business data. Even though organisations go through major transformation, expensive projects such as data migrations, e.g. to data lakes, data warehouses or the cloud, this still don’t provide enough business insight as a return on investment. Major problems and challenges still remain;
-
Data Silos and lack of unified data view: Within organisations, data is scattered across multiple disconnected databases, SasS (Software as as Service) applications and cloud platforms struggle to unify data for data virtualisation and AI models to consume. Within large organisations, different business units use inconsistent terminology to define important business data points and concepts. This results in misalignment and poor data quality, risking the accuracy of business intelligence and insight.
-
Heavy dependence and reliance on IT and Data Engineering: Business users are unable query data themselves and must wait for IT teams to process any requests. Users are victim to the speed in which this IT backlog is cleared. Any software customisation require expensive and time consuming development, slowing down decision-making.
-
Poor data quality and inconsistency: If organisations don’t prioritise data quality management it results in inaccurate, incomplete, inconsistent, outdated or duplicated data scattered over multiple systems. This leads AI models, reports, and business intelligence tools to generate flawed and untrustworthy insights that leads to bad decision-making, compliance risk and even financial losses. Debates over whose data is right creates unnecessary tension between teams.
-
Complex Infrastructure: Having a combination of on-premise systems, SasS products and cloud frameworks vastly increases the complexity of data integration and management. Unchecked, this can lead to compliance, security and regulatory violations.
-
Complexity in AI & ML model development: AI models require consistent, labeled, up-to-date and contextualised data. When the data comes from multiple sources with no consistency and in different formats makes it a challenge for AI models to predict the accurate outcome.
Introduction
If you carefully read through the above it is clear that something is needed to provide the business knowledge and flexibility to expose business data in more unified, business-friendly manner; this abstract layer is called the Semantic Layer.
A semantic layer is a framework that organises and abstracts organisational data and serves as a data connector for business users and IT systems. Semantic layers exist between the database and the IT applications used by end users. It provides a simplified and consistent data view for the user, and hides the complexity of the underlying data sources. In simple terms, it defines all of the rules and relationships that can exist between the data elements and provides a common vocabulary for data in business terms. This logical layer helps to map the physical data structures to create a conceptual data model. One classic example is the definition of “sales” for the sales team versus “revenue” for the finance department, arguable these can be considered synonymous. As a result, a well defined semantic layer ensures the business uses consistent language, avoiding confusion and ambiguity during data analysis. With this in place users can then easily interact with the data, without requiring technical knowledge of their data sources.
Components of Semantic Layer
A semantic layer is not single platform or application but rather the approach to solving business problems. This is achieved by following a process of managing data to capture the business context and designs to optimise the end user experience. Each of the concepts shown in the illustration and further explained below:
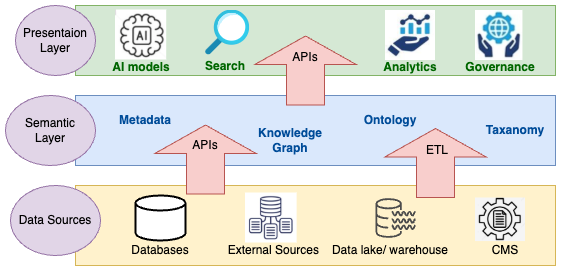
Metadata
Metadata is the backbone of a semantic layer, providing essential context, organisation, and governance to the underlying data. It acts as a structured description of datasets, enabling users, applications, and AI models to understand, locate, and efficiently use data. A well-implemented metadata strategy simplifies data discovery, enhances governance, and ensures consistent data usage across an organisation. In essence, any data stored, is governed by a single sourced metalanguage.
Taxonomy
A business taxonomy is a structured classification system that defines relationships between business concepts. This ensures consistent naming conventions, standardised definitions, and clear organisational structures. When integrated into a semantic layer, a taxonomy compliments metadata by providing an additional layer of organization, making it easier to search, classify, and understand business data. For example, imagine a company selling thousands of products across multiple regions. Without a proper taxonomy one team calls could call a product “Laptop”, while another uses “Notebook”.
Ontology
Traditional tabular data models store data in rows and columns but often fail to capture the deeper meaning of relationships between data points. Ontology enables a shift from data-centric to relationship-centric data modeling, which is essential for modern AI, analytics, and business intelligence.
Ontology is a formal representation of knowledge within a specific domain or subject area. It goes beyond simple taxonomy (hierarchical classification) and metadata (descriptive attributes) by capturing the meaning of relationships between different data elements.
A publishing ontology could represent the relationships between authors, books, publishers, and locations:
-
Author → Writes → Book
-
Publisher → Publishes → Book
-
Author → Works with → Publisher
-
Book → Available in → Location
Knowledge Graph
A Knowledge Graph is a structured, graph-based representation of data where entities (nodes) are connected by relationships (edges), allowing contextual understanding and semantic reasoning over interconnected business data.
In the context of a semantic layer, a knowledge graph applies ontological schemas to real-world data and content, that enables organisations to:
-
Connect diverse, heterogeneous data sources into a unified knowledge model.
-
Link entities and relationships to create meaningful data connections.
-
Store business rules and logic alongside data, making analytics more intelligent.
-
Traverse relationships efficiently, enabling complex queries across linked data.
Unlike traditional relational databases, where data is stored in static tables, knowledge graphs dynamically link concepts, relationships, and rules, making them perfect for AI-powered search, analytics, and automation.
So what can be done? Understand how our flagship product Graphshare bridges this problem below:
How Graphshare Enables a Semantic Layer with Metadata Management and Knowledge Graphs
Graphshare, powered by its innovative graph-based platform and Neo4j graph database technology, provides a robust solution for organisations seeking to implement a semantic layer. This is done through advanced metadata management and knowledge graph capabilities. By addressing the challenges of data silos, inconsistent terminologies, poor data quality, and complex AI/ML model development; Graphshare transforms rigid, semantically-poor data into flexible, semantically-rich, graph-based data ecosystems.
Below, we explore how Graphshare delivers a semantic layer to empower organizations with unified, business-friendly, and intelligent data access.
Comprehensive Metadata Management
Graphshare offers a fully configurable metadata management system that serves as the backbone of it’s semantic layer. Metadata, which provides critical context and governance for data, is seamlessly integrated into Graphshare’s platform.
-
Simplify Data Discovery: Graphshare’s metadata management enables users to locate and understand datasets efficiently, regardless of their underlying sources. By providing structured descriptions of data, it ensures that business users, applications, and AI models can access relevant data without needing deep technical expertise. This directly addresses the blog’s challenge of data silos, enabling a unified data view.
-
Enhance Governance: With configurable metadata, Graphshare ensures consistent data usage across the organization, reducing inconsistencies and improving data quality. This mitigates the risks of inaccurate or duplicated data, which can lead to flawed insights, compliance issues, or financial losses, as highlighted in the blog.
-
Integrate with Corporate Systems: Graphshare’s full set of REST APIs allows seamless integration with existing corporate landscapes, enabling metadata to flow effortlessly between on-premises systems, SaaS applications, and cloud platforms. This tackles the challenge of complex infrastructure by providing a flexible, interoperable solution that avoids vendor lock-in.
Knowledge Graphs Powered by Neo4j
Graphshare leverages Neo4j, a leading graph database platform, to build dynamic and scalable knowledge graphs that form the core of its semantic layer. These knowledge graphs can connect heterogeneous data sources providing a unified model, capturing relationships and business logic in a way that traditional relational databases cannot. Key benefits include:
-
Relationship-Centric Data Modeling: Unlike tabular data models that store data in rigid rows and columns, Graphshare’s knowledge graphs focus on relationships between entities (e.g., customers, products, transactions). This aligns with this blog’s emphasis on ontology-driven, relationship-centric modeling, enabling and unlocking deeper insights and more intelligent analytics. For instance, organisations can model relationships like Customer → Purchases → Product or Product → Available in → Region to enable personalised recommendations and regional sales analysis.
-
Semantic Reasoning and Contextual Understanding: Graphshare’s knowledge graphs apply ontological schemas to real-world data, allowing organizations to link entities and relationships meaningfully. This enables semantic reasoning, where complex queries can traverse relationships efficiently, addressing the limitations of traditional databases for AI and analytics.
-
Dynamic and Scalable: Neo4j’s high-performance graph traversal capabilities ensure that Graphshare’s knowledge graphs can handle large, interconnected datasets while maintaining high query performance. This scalability is crucial for organisations dealing with complex infrastructures.
-
Integration with AI and ML: Graphshare’s knowledge graphs provide clean, contextualised, and up-to-date data, addressing the blog’s challenge of complexity in AI/ML model development. By structuring data as nodes and edges, Graphshare supports Retrieval Augmented Generation (RAG) reducing hallucinations in AI models, ensuring more accurate predictions.