Generative AI is transforming the way businesses generate content — from text and images to videos and code. At the heart of this revolution lie large language models (LLMs) like OpenAI's ChatGPT and Amazon Bedrock.
But while these models exhibit remarkable fluency and creativity, they grapple with serious challenges in enterprise settings — especially around domain-specific context and the risk of hallucinations.
This is where Graphshare steps in, leveraging Retrieval-Augmented Generation (RAG) to enhance precision, trustworthiness, and usability.
Key Takeaways
- LLMs alone are not sufficient for enterprise use — they lack domain context and can hallucinate
- RAG bridges this gap by injecting verified, organisation-specific data into the generation process
- Graphshare uses a knowledge graph-driven approach (GraphRAG) for more precise, relationship-aware retrieval
- The result: factual, verifiable, and organisation-specific AI responses with full traceability
The Challenge: Why LLMs Alone Are Not Enough
Despite their impressive capabilities, LLMs fall short in specialised domains like medicine, law, or engineering.
Domain-Specific Limitations
- Superficial Understanding — LLMs may produce plausible-sounding answers that lack technical depth
- Generic Outputs — Without exposure to niche content, models return vague or evasive responses
- Terminology Gaps — Industry jargon, abbreviations, and nuanced phrases are often misunderstood
- No Organisational Alignment — LLMs trained on general web data do not understand proprietary processes, formats, or methodologies
The Hallucination Problem
- False Confidence — LLMs can generate completely inaccurate information that sounds highly convincing
- Data Gaps — Models trained on outdated or biased data may mislead users
- Overgeneralisation — They can inappropriately combine facts, creating misinformation
The Solution: Retrieval-Augmented Generation (RAG)
RAG works by injecting context from trusted external data sources into the LLM's generation process — ensuring outputs are both accurate and verifiable.
This is done by querying a knowledge base based on the intent in the user's question. There are two main approaches:
- Vector Database (VectorRAG) — semantic similarity search over unstructured content
- Knowledge Graph (GraphRAG) — structured traversal of entity relationships
In simple terms, RAG allows enterprises to feed their own internal, verified content into the LLM pipeline. The result is reduced hallucinations and dramatically improved domain-specific response quality.
How Graphshare Implements RAG
Graphshare supercharges enterprise AI by integrating RAG through a knowledge graph-driven approach (GraphRAG). The following diagram illustrates the core workflow:
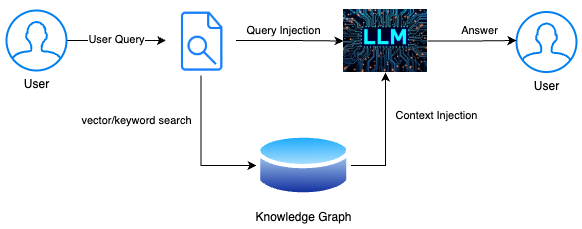
Step 1: User Query
The user submits a natural language question — for example:
"What steps are involved in our vendor onboarding process?"
Step 2: Retrieval via GraphRAG
Instead of relying on keyword or vector searches alone, Graphshare taps into a knowledge graph — a structured map of how internal data is related.
This allows Graphshare to:
- Understand domain-specific terminology
- Follow relationships between entities (documents, processes, people, and tools)
- Retrieve information based on context and connection, not just content similarity
Step 3: Context Injection
The retrieved content is appended as context to the user's original query. This injected context — pulled directly from the trusted knowledge base — gives the LLM the factual grounding it needs to avoid hallucinations.
Step 4: LLM Generation
With both the original question and enriched context, the LLM generates a response. Because it is guided by accurate, organisation-specific data, the answer is not only fluent but also factual, verifiable, and tailored to the enterprise environment.
Step 5: User Receives the Answer
The final output is delivered — a clear, actionable answer rooted in enterprise knowledge, with full traceability back to source data when needed.
Why Graphshare + RAG Is a Game-Changer
- Reduces Hallucinations — Grounding responses in real company data ensures factual accuracy
- Accelerates Onboarding — Employees can instantly query internal systems without sifting through documents
- Enhances Decision-Making — Business users get consistent, high-quality answers aligned with internal best practices
- Customisable Knowledge Base — Graphshare's meta language is easy to customise for different requirements
Looking Ahead
As enterprises push forward into the AI era, it is critical to recognise the limits of LLMs and deploy frameworks that ground their outputs in reality.
Graphshare, powered by RAG, offers the ideal bridge between generative intelligence and reliable enterprise knowledge — enabling smarter, faster, and safer decisions across your organisation.
Ready to see how Graphshare can transform your enterprise AI? Get in touch to start the conversation.