In my last post, I argued that deploying LLM-based agents into enterprise workflows without an explicit finite state machine is architecturally bankrupt. The precondition problem, the auditability requirement, the need to scope uncertainty — all of it points toward Pattern A: deterministic workflow structure with probabilistic intelligence operating within it.
Several of you pushed back, and two objections came up repeatedly. Both are fair. And both point toward the same solution.
Key Takeaways
- Pattern A was never "rigid FSM with no probabilistic reasoning". It already is the middle ground — deterministic structure governing where and how probabilistic reasoning is applied
- A well-designed FSM based on outcomes stays compact and stable. If your state machine is sprawling, the state machine isn't the problem — your modelling is
- Most enterprise platforms maintain workflow, data, and access control as separate hand-crafted layers. An affordance engine derives the available actions from the data model itself, so workflow structure is a live property of the domain, not a brittle artefact alongside it
- Affordance engines solve the capability discovery problem at scale: instead of giving an LLM agent a static catalogue of every tool it could ever call, you present only what's available right now, given context, role, and state
- A properly designed affordance engine is UI-independent — the same engine serves human users and AI agents through the same governed interface. Integrating agents stops being an architecture problem and becomes a packaging problem
The Objections Worth Addressing
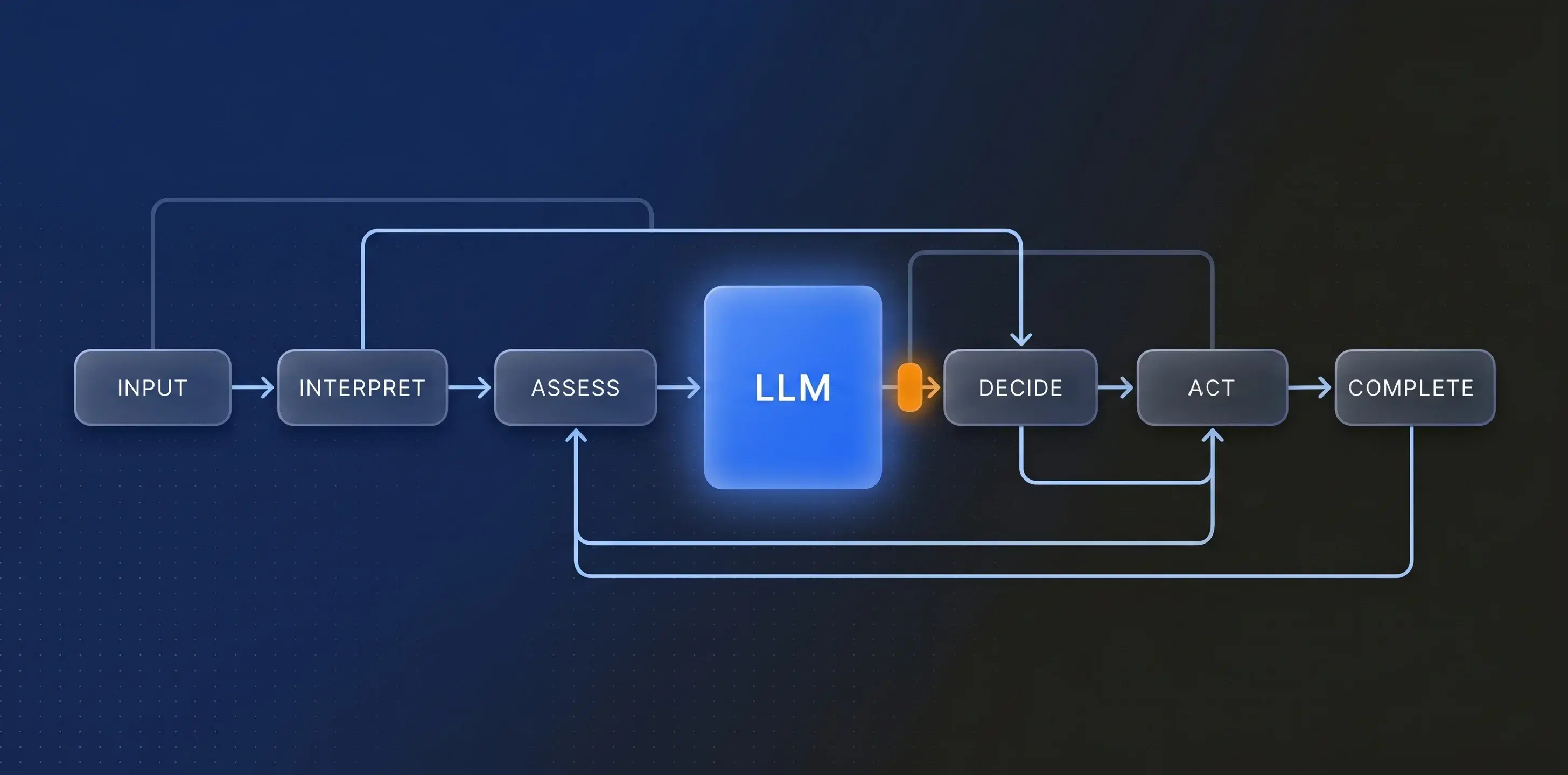
"You've set up a false dichotomy." Several readers argued that the choice between a rigid FSM and a free-roaming LLM isn't binary — that there's a middle ground where the LLM operates within declared constraints or invariants rather than following a predefined state graph. But this misreads the argument. Pattern A was never "rigid FSM with no room for probabilistic reasoning." The entire point of the fuzzy guards discussion was that probabilistic agents operate within the FSM — evaluating conditions, exercising judgement, making assessments — and their outputs feed the deterministic workflow as categorical decisions. Pattern A already is the middle ground. The insight wasn't "choose determinism over probabilism." It was: use deterministic structure to govern where and how probabilistic reasoning is applied. The architecture supports both. That's what makes it work.
"FSMs don't scale." This one comes up a lot, and I have some sympathy — but only for the people who've suffered it, not for the argument itself. When states proliferate and transitions multiply until the graph becomes unmaintainable, the problem isn't the finite state machine. The problem is that someone modelled outputs instead of outcomes. They created a state for every intermediate artefact, every permutation of data, every micro-step in a procedure — instead of asking the only question that matters: what are the meaningful business states this entity can be in?
A well-designed FSM based on outcomes stays compact and stable. "Defect raised. Under investigation. Fix proposed. Fix approved. Fix verified. Closed." That doesn't explode. It doesn't become a maintenance nightmare. It endures because it reflects the actual shape of the domain, not the accidental complexity of a particular implementation. If your state machine is sprawling, the state machine isn't the problem. Your modelling is.
That said, even a well-designed FSM needs to be implemented somewhere. And this is where the honest conversation about cost and platform starts — because most enterprise technology stacks are not built to support this.
The Implementation Problem Is Real — And It Points Somewhere Uncomfortable
Let's be direct. Most enterprise workflow engines, Business Process Management (BPM) tools, and low-code platforms implement state machines as hand-maintained configuration artefacts: a diagram here, a transition table there, a set of rules bolted on after the fact. The FSM lives alongside the data model but isn't derived from it. Change the domain and you have to change the workflow definition separately. Add AI agents and you need to build a separate orchestration layer on top. Add role-based access controls and you're maintaining yet another parallel structure.
This is the real cost objection — and it's legitimate. Not because FSMs are wrong, but because the platforms most enterprises run on were never designed to make FSMs a natural consequence of the data model. They were designed for a world where workflows were drawn by analysts, handed to developers, and frozen into production. The workflow was a specification, not a living property of the system.
If you want the architecture I described in Part 1 — deterministic structure with probabilistic agents operating within it, fuzzy guards at lifecycle gateways, auditability and composability as first-class properties — and you want it without the implementation rigidity that makes traditional FSMs a maintenance burden, then you need a different kind of platform. Specifically, you need an affordance engine.
And no, you probably can't bolt one onto what you've got. This is a foundational architectural choice, not a feature you add. And before someone suggests it: "adding a semantic layer" won't cut it either. A semantic layer over a structurally flat data model is lipstick on a pig — it gives an LLM a richer vocabulary for describing your data, but it doesn't give it any understanding of what actions are legal, what state an entity is in, or what transitions are available. Semantics without affordances is description without agency.
Affordances: From Interaction Design to Workflow Architecture
The concept of an affordance comes from perceptual psychology, via Don Norman's popularisation in design: an affordance is what an environment offers to an actor. A door handle affords pulling. A flat plate affords pushing. The actor doesn't need a manual. The environment communicates what's possible.
The FSM is still there — the guarantees are real, the transitions are deterministic, the guards are enforced. But it's not a diagram someone drew and a developer hard-coded. It's a live property of the data. Change the model and the affordances follow. Add a new business rule and it takes effect everywhere that rule applies, without editing a workflow diagram. The structure grows with the domain because it is the domain.
This isn't a theoretical distinction. It's the difference between a platform where every new process requires a workflow engineering project, and one where the workflow is an emergent property of a well-modelled domain.
Why This Is Exactly What LLM Agents Need
Here's where it gets interesting. One of the fundamental challenges in deploying LLM agents into enterprise systems is capability discovery: how does the agent know what it can do?
The current industry answer is tool descriptions. You give the LLM a list of available functions with parameter schemas and natural language descriptions, and the model decides which to call based on its interpretation of the task. This works for simple cases but breaks down quickly at scale. Fifty tools? Manageable. Five hundred? The context window fills up. The model confuses similar tools. It hallucinates tool names. It calls functions in the wrong order because it has no structural understanding of the workflow it's operating within.
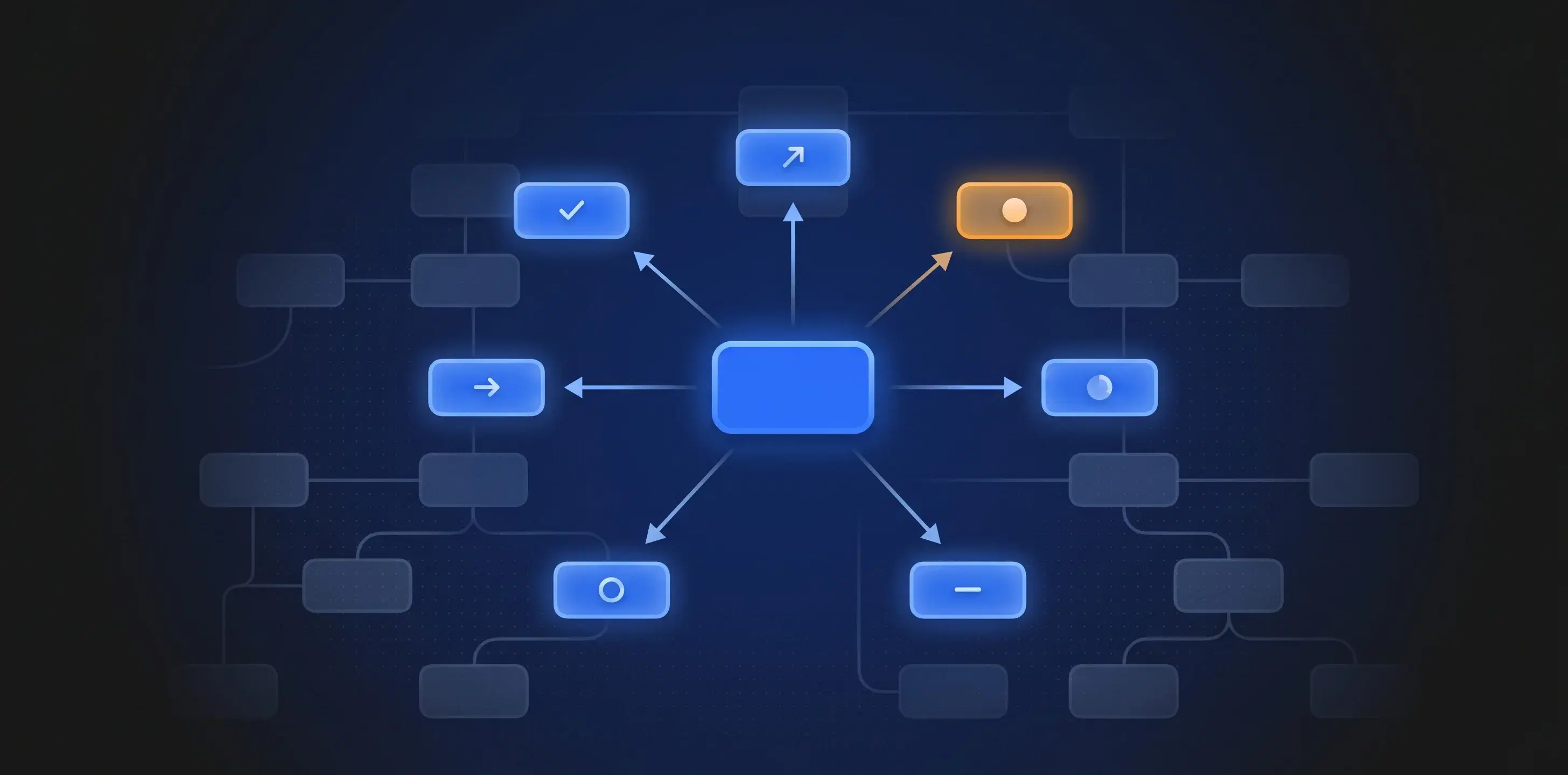
An affordance engine solves this naturally. Instead of presenting the agent with a static catalogue of everything it could ever do and hoping it picks correctly, you present it with what it can do right now, given the current state of the entities it's working with, the role it's operating in, and the point it's reached in the workflow.
The agent doesn't need to reason about preconditions — the affordance engine has already resolved them. The agent doesn't need to figure out the legal ordering of operations — only the currently legal operations are presented. The agent doesn't need to understand the full complexity of the domain's state model — it only sees the slice that's relevant to its current context.
This is a fundamentally different relationship between the LLM and the system it's operating within. The LLM isn't navigating a maze by reasoning about walls it can't see. It's standing in a room where the available doors are clearly marked, and it's choosing which one to walk through. The intelligence is in the choice. The structure is in the room.
The UI-Independence Insight
There's a deeper point here that I think the industry hasn't fully grasped yet. If your affordance engine is designed properly, it's UI-independent. The same engine that presents available actions to a human user through a graphical interface can present them to an LLM agent through an API. The affordances don't change based on who — or what — is consuming them. The business rules, the state constraints, the role-based access controls, the lifecycle governance — all of it applies identically whether the actor is a person clicking a button or an agent making an API call.
I find this point worth dwelling on, because much of the current enterprise AI conversation assumes that deploying agents requires building a new control plane — a separate governance layer, a separate orchestration framework, a separate security model. If your affordance engine is already UI-independent, you don't need any of that. The control plane already exists. The agent is just another consumer of it.
What This Actually Looks Like
Let me make this concrete. Consider an entity — say, an asset, a project, a defect, a capital expenditure proposal — that exists in a particular state within a lifecycle. A human user opens that entity in their interface. The affordance engine evaluates: what state is this entity in? What role does this user hold? What business rules apply? What transitions are legal? And it presents the available actions: approve, reject, escalate, request information, assign, close.
Now replace the human user with an LLM agent. The agent queries the same affordance engine for the same entity. It receives the same set of available actions, governed by the same rules. It applies its probabilistic reasoning — interpreting context, weighing evidence, assessing the situation — and selects an action. The affordance engine validates the selection, executes the transition, and the entity moves to its next state.
The workflow was never defined as a separate state machine document. It lives in the data model, the business rules, and the affordance engine. It's deterministic at the boundaries. It's flexible in the middle. And it serves both human and artificial intelligence without a separate architecture for each.
Where This Takes Us
I started this series arguing that enterprise AI agents need the discipline of finite state machines. I still believe that. But the FSM doesn't have to look the way it did twenty years ago. A modern affordance engine gives you the same guarantees — legal transitions, enforced preconditions, auditability, composability — without the brittleness that made traditional state machines a maintenance burden.
More importantly, it resolves the capability discovery problem that is, I believe, the single biggest bottleneck in scaling LLM agents across enterprise workflows. The agent doesn't need to be omniscient. It doesn't need the full map. It just needs to know what's available right now — and an affordance engine is purpose-built to answer exactly that question.
This is where my thinking has landed, but I'm aware it raises as many questions as it answers. How do you model affordances for workflows that cross organisational boundaries? How do you handle affordance conflicts when multiple agents operate on the same entity? What does testing look like when the workflow is emergent rather than predefined?
I have views on all of these, but I'd rather hear yours first. Where does this argument break for you?